R-CNN
Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation."
Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
R-CNN은 object detection의 시작이라고 할 수 있는 논문으로 이 이후 더 발전된 다양한 R-CNN 계열 network들이 제안되었습니다. R-CNN의 방법과 순서는 다음과 같은 3개의 module으로 구성됩니다.
- Category에 독립적인 region proposal : detector에 사용될 영역 후보를 제안합니다.
- Large convolutional neural network : proposal 된 각 region에서 고정된 크기의 feature vector를 추출합니다.
- Class-specific 선형 SVM 집합 : feature vector를 기반으로 SVM을 이용해 해당 영역의 class를 예측합니다.

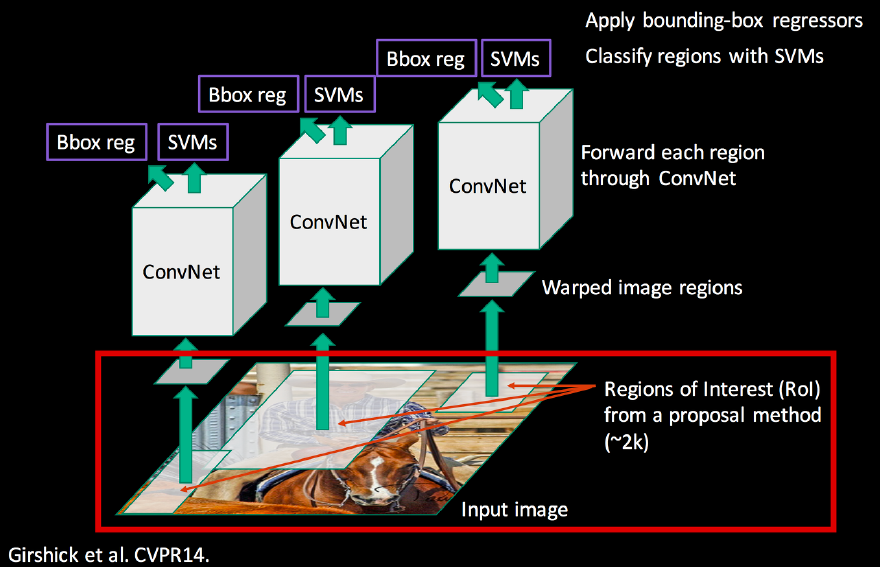
R-CNN이 object detection을 수행하는 순서는 다음과 같습니다.
- Input image에 selective search 방법을 이용해 input image 속 2000개의 영역(RoI)을 선택합니다.
- 선택된 영역들을 크기와 비율에 상관없이 모두 227$\times$227 크기로 바꾸고(warp) AlexNet을 detection task에 맞게 변형한 CNN 네트워크에 넣어줍니다. 그 결과로 4096차원의 feature vector를 얻습니다.
- 이 feature vector을 SVM의 input으로 이용하여 해당 object의 class를 예측합니다. 많이 겹쳐지는 box에 대해서는 greedy non-maximum suppression을 이용하여 높은 score의 bbox만을 남깁니다.
- Selective search로 제안된 bbox의 위치를 더 정확하게 하기 위해 bounding box regression을 수행해 box의 위치를 조절합니다.
단점
- 모든 이미지에 대해 Selective search를 통해 얻은 2000개의 영역 이미지 모두 CNN 네트워크를 통과시키기 때문에 시간이 매우 오래 걸립니다.
- CNN, SVM, Bounding box regression 3가지의 모델을 사용해서 전체 모델이 크고 복잡합니다.
- 위 3개의 모델을 모두 따로 사용하기 때문에 SVM과 Bounding box regression의 학습 결과를 CNN에 적용할 수 없습니다.
- 크기를 모두 227$\times$227로 바꾸면서 원래 object의 형태 등이 보존되지 않는 문제가 있습니다.
본 글에서는 생략하지만 R-CNN과 Fast R-CNN 사이에 SPPNet이라는 detection 네트워크에서 RoI의 형태를 유지하고 convolution 할 수 있도록 하였습니다.
Fast R-CNN
Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
R-CNN의 저자는 SPPNet의 아이디어를 참고하여 기존 R-CNN의 성능을 크게 높인 Fast R-CNN을 제안하였습니다. 기존의 R-CNN은 위에서 이야기했던 것과 같이 다음과 같은 큰 단점이 있었습니다.
- Training이 multi-stage pipeline으로 이루어집니다. R-CNN은 먼저 log loss를 사용하는 ConvNet을 fine-tuning 하고 SVM을 ConvNet의 feature에 fitting 합니다. 마지막 세 번째 training stage에서 bounding-box regressor를 학습합니다.
- Training에 소모되는 공간과 시간이 매우 큽니다. SVM과 bounding-box regressor 학습의 경우 각 이미지의 object proposal로부터 feature를 추출하고 disk에 기록해둡니다. VGG16과 같이 매우 깊은 네트워크를 사용하면 문제가 더 심해집니다.
- Detection 속도가 매우 느립니다. Test 단계에서 VGG를 이용한 detection은 GPU를 사용하더라도 이미지당 47초의 시간이 소모됩니다.
SPPNet에 남아있던 가장 큰 문제점은 multi-stage pipeline 학습과 SPP(Spatial Pyramid Pooling) 이전의 covolution layer를 업데이트할 수 없는 것이었습니다. Fast R-CNN에서는 multi-task loss를 사용하여 single-stage로 학습하고 모든 네트워크의 layer들을 학습을 통해 업데이트할 수 있도록 하였습니다.


Fast R-CNN이 object detection을 수행하는 순서는 다음과 같습니다.
- 이미지 전체를 ConvNet을 통과하여 feature map을 얻습니다.
- 이제는 Selective Search를 통해 찾아진 모든 RoI들에 대해 Convolution을 수행하지 않고 전체 이미지를 통해 얻어진 feature map의 해당 영역들을 사용합니다. 이렇게 얻어진 각 RoI에 RoI pooling을 수행하여 모든 RoI들이 고정된 크기의 feature vector를 가지게 됩니다.
- 각 feature vector들은 FC layer를 통과한 뒤 두 output layer로 전달됩니다.
- SVM을 더 이상 사용하지 않고 softmax를 사용하여 object의 class를 예측합니다.
- Bounding-box regressor를 이용하여 bounding box의 위치를 조정합니다.
RoI pooling
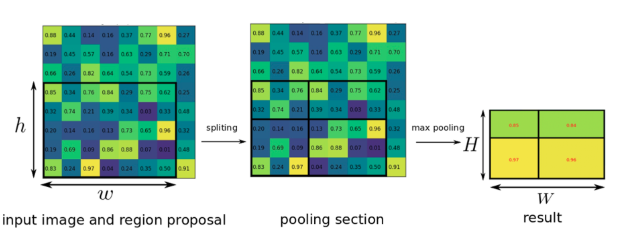
각각의 RoI에서 고정된 크기의 feature vector를 추출하기 위해서 RoI를 정해진 개수로 나누고 각 grid에 maxpooling을 수행합니다. 그림에서와 같이 $h=5, w=7$이고 $H, W=2$인 경우 4개의 grid가 생성되고 각 grid에는 해당 grid 내의 최댓값이 입력됩니다. 이는 SPPNet의 pyramid pooling을 하나의 pyramid level에 대해 수행하는 것과 동일합니다. 이렇게 하여 크기가 다른 RoI들에 대해서도 항상 같은 크기의 feature vector를 생성할 수 있습니다.
Back propagation
Fast R-CNN은 모든 layer를 학습을 통해 업데이트한다고 하였으니 ROI pooling 이전의 input에 대해서도 계산이 가능해야 합니다. $x_i$가 RoI pooling layer에 입력된 $i$번째 activation input이라고 하고, $y_{rj}$가 $r$번째 RoI가 input으로 들어왔을 때 layer의 $j$번째 output이라고 했을 때 식은 다음과 같습니다.
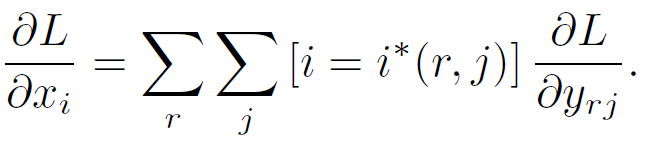
간단히 말하면 $x_i$는 feature map의 한 pixel값이고 이 값이 RoI를 $H\times W$로 나눈 grid(sub-window) 내부의 값들 중 최댓값이라면 max pooling을 수행하는 RoI pooling에서 살아남아 $y_{rj}$값에 영향을 줄 수 있습니다. 위 식에서 indicator function 내부의 $i^*(r, j)$는 $i^*(r,j)=\mathrm{argmax}_{i' \in \mathcal{R}(r,j)}x_{i'}$이고 $\mathcal{R}(r,j)$는 아래와 같이 $y_{rj}$값이 되는 sub-window 내부 값들의 인덱스 set입니다. 즉 $i^*(r,j)$는 RoI와 sub-window가 정해졌을 때 해당 sub-window값들 중 최댓값의 index이므로 위 식은 $i=i^*(r, j)$일 때, 다시 말해 위에서 이야기했던 것처럼 $x_i$가 sub-window의 최댓값일 때만을 합해 계산을 하게 되는 것입니다. 아래 이미지를 참고하시면 좀 더 이해하기 쉽습니다.

덕분에 R-CNN에 비해 속도와 성능면에서 매우 좋아졌지만 아직까지는 RoI를 찾는데 selective search 방법을 사용하여 해당 부분의 시간 소모가 매우 크다는 문제가 남아있었습니다.
Faster R-CNN
Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems 28 (2015).
Fast R-CNN에서 selective search 방법을 사용하여 시간이 오래 걸렸던 문제를 해결하기 위해 Region Proposal 단계를 Network를 이용해 Object detection을 수행하였습니다. Training 단계에서 RPN(Region Proposal Network)의 output region을 Non-maximum suppression(NMS) 한 결과 region의 개수가 약 2000개로 이전 Fast R-CNN의 selective search 결과 개수와 비슷하지만 속도와 정확도에서 훨씬 좋은 결과를 보입니다.
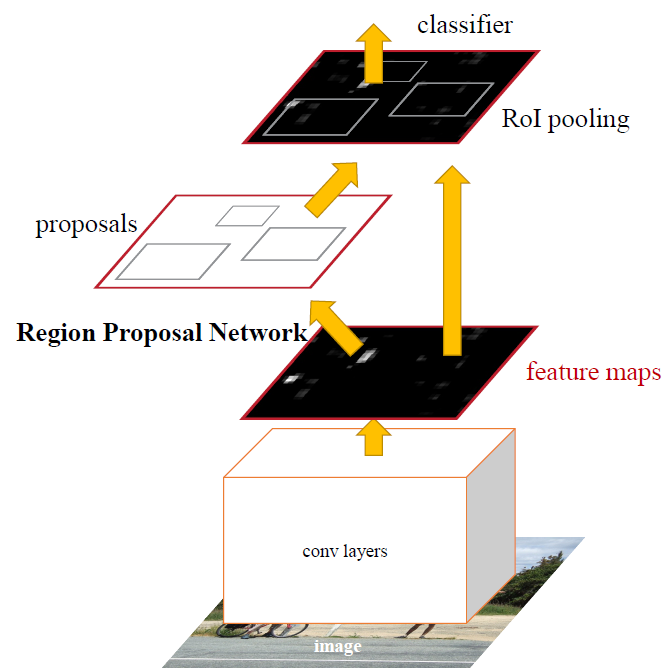
Region Proposal Network의 순서는 다음과 같습니다.
- 먼저 Region Proposal Network 이전에 Conv layers를 통과해 얻은 feature map을 사용합니다.
- 이 Feature map을 $n\times n$(논문에서는 $n=3$) kernel을 이용하여 convolution을 수행(intermediate layer)하여 256차원의 채널을 가지는 feature map을 다시 얻습니다.
- 새로 얻은 feature map을 box-regression layer($reg$)와 box-classification layer($cls$)에 보내는데 이때 각각 $reg$용 $1\times 1$ convolution layer와 $cls$용 $1\times 1$ convolution layer를 거쳐 regressioni과 classification을 수행하도록 합니다.
- 아래 방법으로 각 anchor box에 대한 정보를 계산합니다. 1번에서 얻은 convolution featrue map이 $W\times H$이고 anchor box의 종류가 $k$개일 때, 만들어진 전체 anchor box의 수는 $WHk$개가 됩니다.
- classification : class의 분류가 아니라 object가 있는지 없는지를 분류합니다. $1\times 1$ covolution layer를 거쳐 $k$개의 서로 다른 anchor box마다 object가 있는지, 없는지에 해당하는 총 $2k$개의 channel이 생성됩니다.
- regression : $1\times 1$ covolution layer를 거쳐 $k$개의 서로다른 anchor box마다 anchor box의 위치와 크기를 조절하기 위한 4개의 parameter를 계산합니다.
- 4번에서 얻은 값들을 이용해 RoI를 결정합니다. RPN의 classification 결과를 이용해 NMS를 수행하고, 이때 IoU의 threshold는 0.7으로 설정합니다. 이후 남은 것들 중 top-N rank의 proposal region을 detection에 사용하게 됩니다. 이때 N값에 따라 training시에는 이미지당 약 2000개, test시에는 약 300개의 proposal region을 사용하였습니다.

마지막으로 이렇게 얻은 RoI를 feature map에 projection 하여 RoI pooling을 수행하고 Fast R-CNN과 같이 class classification을 수행하여 최종 detection 결과를 얻습니다.
Training
RPN이 제안한 RoI가 정확하지 않다면 detection을 제대로 수행할 수 없습니다. 저자들은 Alternating training이라는 방법을 통해 RPN과 classifier를 번갈아가며 학습시켜 성능을 높이고, RPN과 classifier가 서로 분리된 network를 학습하여 사용하는 대신 하나의 network를 같이 사용하도록 하였습니다. 그 방법은 다음 4단계로 이루어집니다.
- ImageNet으로 pre-train 된 model을 불러오고 region proposal을 위해 RPN을 end-to-end 방식으로 fine tuning 합니다.
- 1단계에서 학습된 RPN이 제안하는 RoI를 이용해 Fast R-CNN의 detection network를 학습시킵니다.
- 이제 처음 convolution layer는 고정시킨 상태로 RPN만을 학습시킵니다. 여기서부터 두 network가 conovlution layer를 공유하게 됩니다.
- 마지막으로 covolution layer는 여전히 고정시킨 상태로 Fast R-CNN의 detection network를 학습시킵니다.
실험 결과 높은 속도와 성능을 얻었고 Fast R-CNN이 당시 detection task에 널리 쓰이면서 좋은 network임을 증명하였습니다. 또, 다양한 ablation study를 통해 각각의 부분이 기여하는 내용을 실험적으로 확인하였습니다.
R-CNN부터 단점을 고쳐가며 end-to-end 방식으로 높은 속도와 정확도를 얻는 Fast R-CNN까지 2 stage 네트워크들을 정리해보았습니다. 이후 Yolo와 SSD 같은 다른 detection network에 대해서도 정리하며 어떤 방법을 사용하고 어떻게 발전해왔는지 정리해볼 예정입니다.