기존의 LiDAR data 기반 3D object detection 방법들은 대부분 hand-crafted 방법을 이용해 feature를 생성하고 RPN에 넣는 방법을 사용했습니다. 본 논문과 같이 Voxel을 사용했던 방법도 있었지만 각각의 voxel을 hand-crafted방법을 통해 feature를 encoding 하였습니다. VoxelNet은 hand-crafted feature 대신 feature extraction과 bounding box prediction을 single stage로 통합하여 end-to-end 방식으로 학습할 수 있는 네트워크를 제안하였습니다.
VoxelNet 이전 PointNet과 PointNet++이라는 유명한 논문들은 point cloud를 다른 변형 없이 point들을 그대로 사용하는데 이는 높은 연산량과 메모리를 필요로 합니다. 또, RPN은 object detection에 효과적이지만 data가 dense 하고 정리된(organized) 상태여야 하는 조건이 있는데 point cloud는 이러한 조건을 만족하지 못합니다.
VoxelNet은 이러한 문제를 해결하기 위해 point cloud를 Voxel로 변형한 뒤 VFE(Voxel Feature Encoding) layer를 통해 voxel feature를 만들게 됩니다. 이후 이 feature를 RPN에 넣어 bounding box를 생성하여 Detection을 수행합니다..
Architecture
VoxelNet은 총 3개의 fuctional block으로 이루어져 있습니다.
- Feature learning network
- Convolutional middle layers
- Region proposal network

1. Feature learning network
Voxel Partition. 먼저 주어진 point cloud를 균일한 3D voxel으로 나눠 구분합니다. 이때 각각 $Z, Y, X$축으로의 크기가 $D, H, W$이고, voxel 하나의 크기를 $v_D, v_H, v_W$라고 정의한다면 공간은 $D', H', W' (D' = D/v_D, H' = H/v_H, W' = W/v_W)$로 나누어집니다. 논문의 실험에서는 $v_D, v_H, v_W = (0.4, 0.4, 0.2)$로 정하였습니다.
Grouping. 이후 같은 voxel 속에 있는 point들을 grouping 합니다. 이때 Point cloud data는 매우 sparse 하고 point의 밀도가 다양하기 때문에 각 voxel 속 point들의 개수도 다양할 것입니다. 그 예가 그림 1에서 1번 voxel처럼 point가 매우 많은 voxel도 있고 3번 voxel처럼 point가 하나도 없는 voxel도 있는 것을 볼 수 있습니다.
Random Sampling. LiDAR를 통해 얻은 point cloud는 수많은 point로 구성되어있기 때문에 모두 사용하기에는 계산량과 메모리 문제가 있고, LiDAR 특성상 가까운 object에 point가 많이 얻어 지기 때문에 이로 인한 bias가 생길 수 있습니다. 이를 방지하기 위해 각 voxel은 최대 $T$개의 point만을 가지도록 random sampling을 수행합니다.
Stacked Voxel Feature Encoding. VoxelNet에서 key innovation이라고 하는 부분으로 VFE layer를 연속적으로 적용합니다. 그림 1에서 VFE Layer-1부터 VFE Layer-n으로 나타내고 있습니다. 하나의 VFE Layer는 아래와 같이 구성됩니다.

Feature는 모두 Point에서 생성하므로 비어있는 voxel에서는 아무 작업도 하지 않습니다. 비어있지 않은 voxel 내의 point들은 $(x_i, y_i, z_i, r_i)$의 형태로 point의 xyz 좌표와 received reflectancd를 feature로 가집니다. 여기서 먼저 voxel 내에 있는 point들의 centroid를 계산합니다. 이 중심점의 좌표가 $(v_x, v_y, v_z)$라면 이제 각 point들에 상대 좌표를 추가하여 $(x_i, y_i, z_i, r_i, x_i - v_x, y_i - v_y, z_i - v_z)$의 형태가 됩니다.
이 feature를 FCN을 거쳐 feature space로 보낸 뒤 element-wise Maxpooling을 통해 voxel 속 모든 point들의 global feature(Locally Aggregated Feature)를 얻습니다. 그리고 이 Locally Aggregated Feature를 Poin-wise Feature들에 모두 concatenate 하여 다음 VFE layer의 input이 될 point-wise concatenated Feature를 생성합니다. 이때 FCN을 거쳐 나온 feature가 $m$차원이라면 concat 이후 point-wise concatenated Feature는 $2m$ 차원이 됩니다. 논문에서는 이를 통해 voxel 내의 point들이 만드는 surface의 형태를 encoding 한다고 이야기했습니다.
이렇게 연속적으로 VFE layer를 거친 뒤 마지막에는 FCN을 거쳐 나온 Point-wise Feature를 바로 Max-pooling 하여 Voxel-wise feature를 얻습니다. 그림 1의 마지막 보라색 막대가 위 과정을 통해 얻어진 $C$차원의 Voxel-wise feature입니다.
Sparse Tensor Representation. sparse 한 point cloud data 특성상 non-empty voxel의 수는 전체 voxel의 약 10% 이하일 것입니다. 이를 해결하기 위해 non-empty voxel의 feature들을 list로 만들어 저장합니다. 이렇게 non-empty voxel feature를 sparse tensor로 표현하면 backpropagation 단계에서 메모리 사용량과 계산 비용이 크게 줄어든다고 합니다. 이는 잠시 후에 자세히 설명합니다.
2. Convolutional Middle Layers
Feature learning network에서 만든 voxel-wise feature들을 convolutional middle layer(3D convolution + BN layer + ReLU layer)를 여러 번 거쳐 receptive field를 넓혀가며 aggregate 합니다. 차원이 늘어났을 뿐 이미지에서의 convolution layer와 같은 역할을 합니다. 논문에서는 3개의 middle layer를 사용하였습니다.
3. Region Proposal Network
Convolutional middle layer를 거쳐 나온 feature를 input으로 하여 class score와 bounding box regression 결과를 얻습니다.
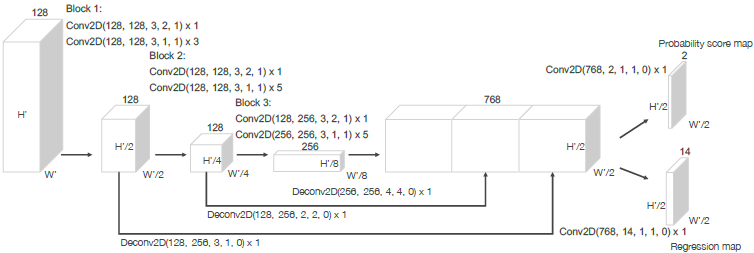
그림의 convolution 연산은 Conv2D($C_{in}, C_{out}, kernel\;size, stride, padding$)을 의미하고 이를 보면 block 하나를 지날 때마다 stride를 2로 하여 $H, W$가 반으로 downsampling 되는 것을 알 수 있습니다. 3개의 fully convolutional layers block을 지나고 난 뒤 각 block에서 나온 feature map은 모두 같은 크기로 upsampling 하여 concat 한 뒤 2D convolution을 거쳐 (1) probability score map과 (2) regression map을 output으로 생성하여 object detection 결과를 output 합니다.
네트워크는 anchor를 이용해 detection 결과를 표현합니다. 이때 anchor는 중심 좌표 $(x, y, z)$, 길이, 폭 높이$(l, w, h)$, $z$축을 기준으로 하는 yaw 회전$(\theta)$ 총 7개의 feature로 표현됩니다. (1) probability score map의 output channel의 수는 2로 이는 각 BEV pixel에서 예측 anchor box를 2개씩 예측하므로 각 anchor box의 socre를 나타내게 됩니다. (2) regression map의 output channel의 수는 2개 anchor box의 7개 feautre regression 결과로 $7\times 2 = 14$가 됩니다.
Loss function
이제 위에서 나온 output을 Ground truch bounding box와 비교하여 loss를 계산합니다. 각 같은 요소들의 값을 계산하는데 다음과 같습니다.

여기서 g가 ground truth, a가 예측한 anchor입니다. 분모의 $d^a$는 예측한 anchor의 대각선 길이로 크기에 따라 값의 차가 달라지는 것을 막기 위해 normalize 하기 위한 값으로 사용되었습니다.

score loss값은 positive anchor box$(p^{pos}_i)$의 score는 1에 가깝게, negative anchor box$(p^{neg}_i)$는 0에 가깝도록 binary cross entropy loss$(L_{cls})$를 사용합니다. regression의 결과는 groung truth 값과 같아지도록 SmoothL1 loss$(L_{reg})$를 사용하여 계산합니다.
여기서 positive, negative는 anchor box와 ground truch box 간의 IoU(Intersection over Union) 값으로 결정됩니다. IoU값이 Car는 0.65, Pedestrian과 Cyclist는 0.5보다 크면 positive anchor, 0.35보다 작으면 negative anchor로 분류합니다. 그 사이의 값을 가지는 anchor는 don't care로 간주하여 loss 계산에 포함하지 않습니다.
Efficient Implementation

Feature learning 단계에서 비어있는 모든 tensor까지 저장하는 것은 이전에 이야기했던 것처럼 효율적이지 못합니다. 또, GPU는 dense한 tensor 연산에 특화되어있는데 point cloud는 sparse하게 분포되어 voxel마다 point 개수의 분포도 매우 다양해서 GPU에 부적합합니다. 때문에 non-empty voxel featuer들만을 dense한 형태로 VFE에 제공하여 GPU의 효율을 높이고 각각의 voxel과 voxel 내의 point들을 병렬 처리할 수 있는 방법을 제안했습니다.
Voxel Input Feature Buffer는 $K\times T\times 7$의 형태를 가지고, Voxel Coordinate Buffer는 $K\times 1\times 3$의 형태를 가집니다. 이때 7은 point의 feautre 차원이고 3은 voxel의 좌표값에 해당합니다. 이때 $K$는 non-empty voxel의 최대 개수이고 $T$는 voxel 하나에 있을 수 있는 최대 point 개수입니다.
처음 모든 point들의 feature를 계산하면서 해당 point가 속한 voxel이 Voxel Coordinate Buffer에 있는지 확인하고, 있다면 그 Voxel에 맞는 Voxel Input Feature Buffer에 추가합니다. 만약 point가 처음 등장한 voxel에 속해있다면 이 Voxel의 좌표를 Voxel Coordinate Buffer에 추가하고 Voxel Input Feature Buffer에 그 point feature를 추가하게 됩니다. 간단히 이야기하면 Voxel Coordinate Buffer에 non-empty Voxel의 좌표를 저장하고, 그 Voxel 내 point들의 feature들을 Voxel Input Feature Buffer에 모아 저장하는 것입니다. 이렇게 최대 T개의 point, K개의 Voxel까지 저장을 하고 만약 point가 T개만큼 꽉 차면 이후 point는 무시하고, T개보다 적은 상태로 끝난다면 나머지에는 0을 채워 넣습니다.
이후 convolutional middle layers와 RPN은 이 dense voxel grid를 이용해 효율적으로 GPU에서 동작하게 됩니다.
Data Augmentation
실험에서 사용한 3개의 Augmentation 방법을 간단히 정리하면 다음과 같습니다.
- Ground truth bounding box를 rotaion, translation 하여 perturbation을 줍니다.
- 모든 Ground truth box와 모든 point cloud에 global scaling을 적용합니다.
- 모든 Ground truth box와 모든 point cloud에 global rotation을 적용합니다.
VoxelNet은 end-to-end 방식으로 높은 성능을 달성하여 pointNet과 마찬가지로 이후 논문들에 영향을 끼치며 현재까지도 높은 인용수를 가지고 있습니다.
감사합니다.